Rethinking Model Evaluation as Narrowing the Socio-Technical Gap
Liao, Q. Vera, and Ziang Xiao. 2025. “Rethinking Model Evaluation as Narrowing the Socio-Technical Gap.” arXiv. https://doi.org/10.48550/arXiv.2306.03100.
Notes
- model-evaluations should be focused on identifying the socio-technical gap so that it can be closed
- socio-technical gap
- the gap between the needs of the user and what the technology can do
- socio-technical gap
- how can socio-technical gap be identified
- from Social science theories
- Realism
- “the situation or context within which the evidence is gathered, in relation to the contexts to which you want your evidence to apply” (Liao and Xiao, 2025, p. 3)
- if an application is studied in a real-setting than in a lab, we would better know how the application would fare in a similar setting better than the insights from the lab
- Ecological validity
- “how well conclusions of a laboratory study apply to the target real-world situation” (Liao and Xiao, 2025, p. 3)
- three dimensions
- context
- “how close the task or test environment is to the target real-world context” (Liao and Xiao, 2025, p. 3)
- human response
- “how well the measurement represents people’s actual response and is appropriate to the constructs that matter” (Liao and Xiao, 2025, p. 3)
- stimuli
- “how well materials used in the test represent what people would encounter in the real-world context” (Liao and Xiao, 2025, p. 3)
- context
- Realism
- from Explainable AI - “Interpretability Evaluation Framework” proposed by Doshi-Velez & Kim (2017)
- Application-grounded evaluation
- “by humans performing real tasks with the target application” (Liao and Xiao, 2025, p. 3)
- Human-grounded evaluation
- “by humans performing simplified tasks such as rating the “quality” of the ex planations, which would not require the costly time, resources, and skills for completing the real task” (Liao and Xiao, 2025, p. 3)
- Functionally-grounded evaluation
- “without involving humans, by proxy metrics based on some formal definitions of human desirable criteria of explanations” (Liao and Xiao, 2025, p. 4)
- Application-grounded evaluation
- from Social science theories
- The evaluation metrics shouldn't come from the NLP community but rather it should come from people for whom a particular tool is designed for
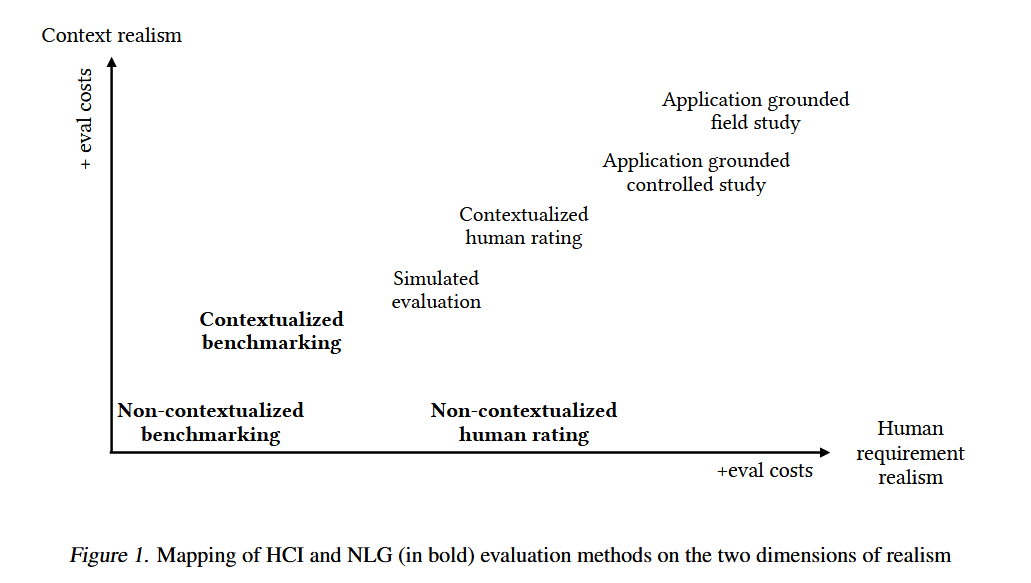
HCI and NLG Evaluation Methods for LLM Evaluation
- Benchmarking
- Non-contextualized benchmarking
- technical NLP benchmark
- Contextualized benchmarking
- HELM provides a taxonomy
- task based benchmarks
- multimeric measurements
- metric should come from the people but not blindly defined based on pre-existing frameworks
- Non-contextualized benchmarking
- Human-rating
- Noncontextualized
- Contextualized
- Application-grounded evaluation
- Controlled
- Field studies
- Simulated evaluation
- use-case grounded simulated evaluation
In-text annotations
"However, these human evaluation practices have also been widely criticized for lacking standardization, reproducibility, and validity for assessing model utility in real-world settings" (Page 1)
"socio-technical gap, a challenge that HCI research has long contemplated regarding the inevitable divide between what a technology can do and what people need in the deployment context" (Page 2)
"there is an inevitable gap between the human requirements in a technology deployment context (we refer to as socio-requirements hereafter to mean context-specific human requirements) and a given technical solution." (Page 2)
"As computational mechanisms to be embedded in diverse social contexts, ML models will inevitably face the socio-technical gap" (Page 2)
"model evaluation should make a research discipline that takes up the mission of understanding and narrowing the socio-technical gap" (Page 2)
"Goal 1 (G1): Studying people’s needs, values, and activities in downstream use cases of models, and distilling principles and representations (e.g., taxonomies of prototypical use cases and socio-requirements) that can guide the evaluation methods of ML technologies." (Page 2)
"Goal 2 (G2): Developing evaluation methods that can provide valid and reliable assessments for whether and how much human needs in different downstream use cases can be satisfied. That is, evaluation methods should aim to be the “first-order approximation” for downstream sociorequirements while articulating their limitations and tradeoffs: e.g. they are proxies for some socio-requirements, and each of them may only represent one aspect of sociorequirements." (Page 2)